이 포스팅은 edwith의 딥러닝 2단계 : 심층 신경망 성능 향상시키기를 듣고 공부 목적으로 작성되었습니다.
How to make Improving Deep Nerual Networks training
어떻게 해야 심층 신경망의 훈련을 향상 시킬 수 있을까??
Keyword : normalize input features ( 입력값의 정규화 )
신경망의 훈련을 빠르게 하는 방법 중 하나 => 입력을 정규화
입력의 정규화의 2단계
① Subtract mean
평균을 빼는 것
-> μ=m1∑i=1mx(i)
x:=x−μ
-> 모든 훈련 샘플에 대해 적용
-> 0의 평균을 갖게 될때까지 훈련 세트를 이동하는 것
② Normalize Variance
분산을 정규화
-> σ2=m1∑i x(i)2
x:=x/σ2
-> 각각의 샘플을 얻어 Vector로 나눠줍니다.
-> X1과 X2의 분산은 이제 모두 1

++one tip
훈련데이터를 확대하는데 사용한다면,,,
test set 정규화할때도 같은 μ 와 σ를 사용해라.
use same μ and σ to normalize test set.
μ , σ2 두개 값이 어떻든
x=x- μ / x/= σ2 두가지 식에 사용하라.
===> 따라서 같은 방식으로 test set을 확장하게 된다.
training set 과 test set 모두 training data 에서 계산된 것과 같은 μ , σ에 의해
정의된 변형이 거치기를 원하기 때문!
왜 입력 특성을 정규화하기를 원할까??
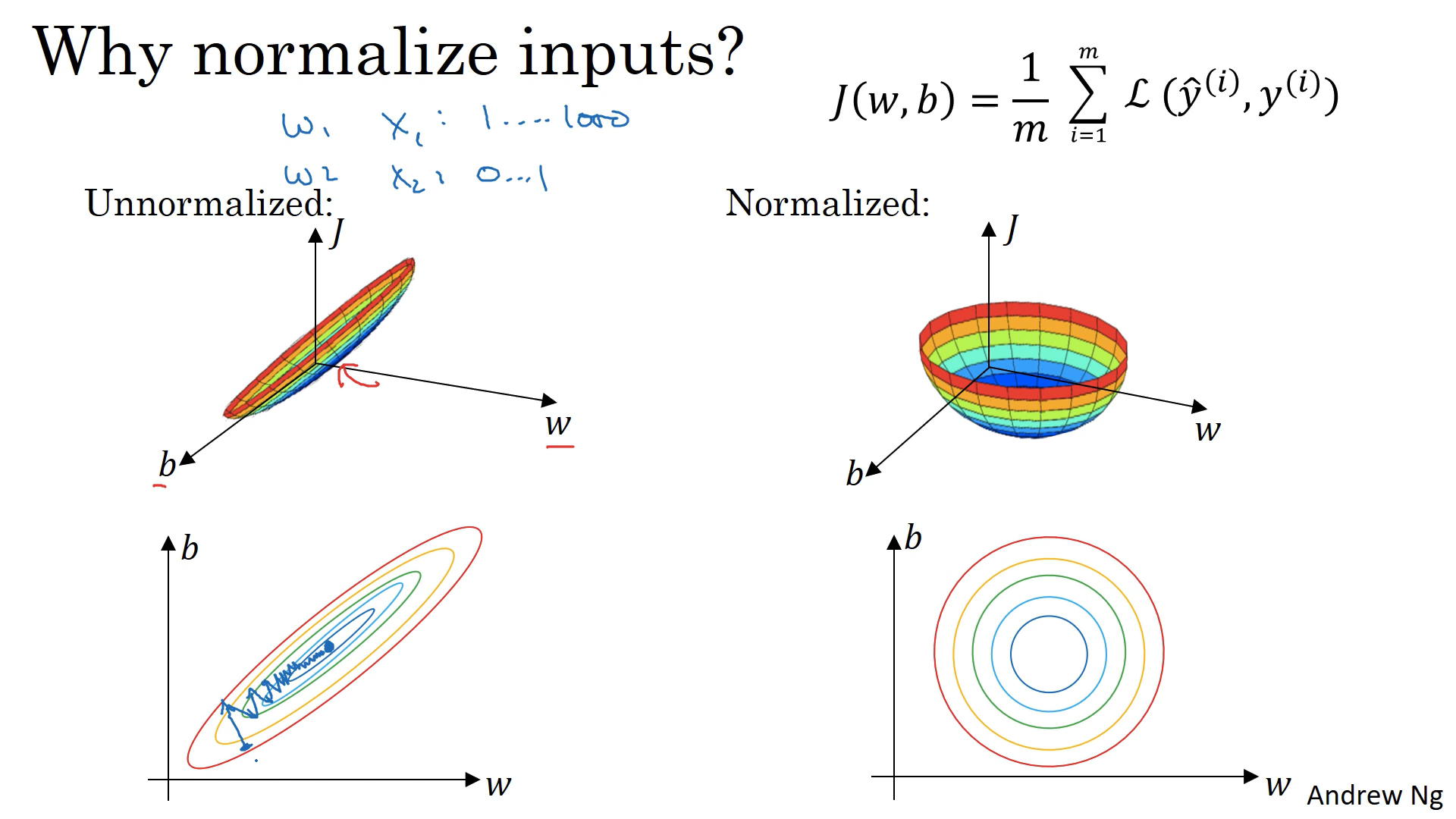
왼쪽 unnormalized - 매우 구부러진 활 처럼 가늘고 긴 모양의 비용함수
만약 특성들이 매우 다른 크기를 갖고 있다면,
매개변수에 대한 비율 값의 범위 w1 , w2 굉장히 다른 값을 가질 것이다.
=> 매우 가늘고 긴 모양 / 등고선을 그려봐도 가늘고 긴 함수
unnormalized 에서 경사하강법을 쓰면 매우 작은 학습률을 사용하게 됨.
(경사하강법 - 최종적으로 최솟값에 이르는 길을 찾기 전까지
앞 뒤로 왔다갔다 하기 위해 많은 단계가 필요함)
오른쪽 normalized - J 비용함수가 평균적으로 대칭적인 모양을 갖게 된다.
원 모양의 등고선의 경우 어디서 시작하든 경사하강법은 최솟값으로 바로 갈 수 있다.
큰 스텝으로 전진할 수 있다.
특성이 비슷한 크기를 갖을 때, 비용함수가 더 둥글고 최적화하기 쉬운 모습이 된다
입력 특성 값의 범위가 dramatic하게 다른 범위는 최적화 알고리즘에 방해가 된다!
결론
모든 것을 0의 평균으로 설정하고 이전 슬라이드처럼 모든 특성을 비슷한 크기로 보장할 수 있는 분산을 설정하면 학습 알고리즘이 빠르게 실행되는 것을 도울 것입니다.
따라서 만약 입력 특성이 매우 다른 크기를 갖는다면 특성을정규화하는것이 중요합니다.
그러나 이런 정규화는 어떤 해도 가하지 않기 때문에 되도록 하는 것을 추천드립니다.
만약 특성이 비슷한 크기를 갖는다면 이 단계는 그렇게 중요하지 않습니다.
'Deep Learning' 카테고리의 다른 글
| [Deep Learning] 딥러닝 소개 : 딥러닝이란?/ Neural Network 신경망/ 지도학습/ 최근 딥러닝이 뜨고 있는 이유 (0) | 2020.01.21 |
|---|
